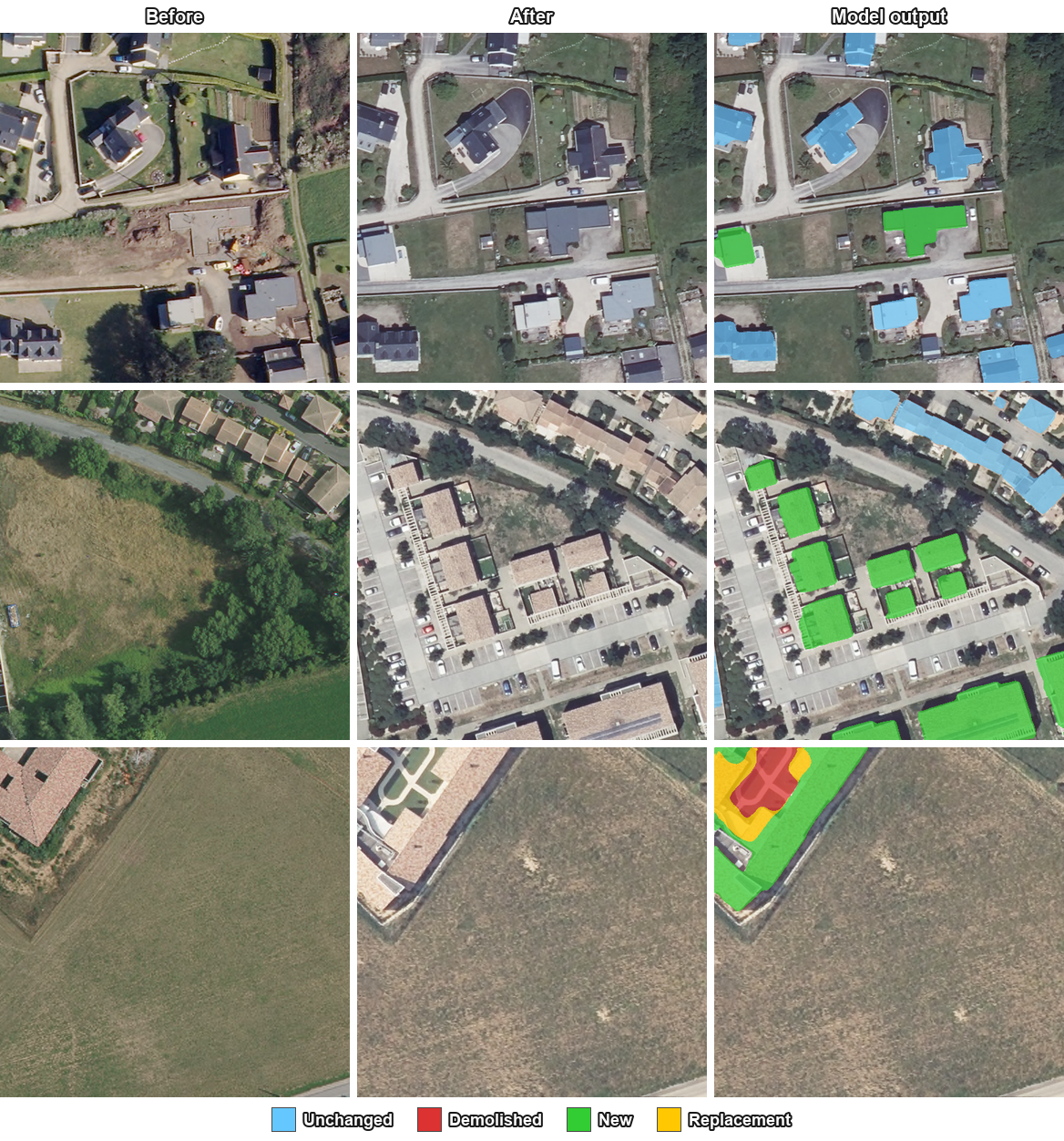
I'm releasing MBCTD, a deep learning model that detects demolished, new, and unchanged buildings independently per pixel, including replacement sites that single-label models can't represent.
Today I'm releasing MBCTD (Multi-Label Building Change Type Detection), a deep learning model for per-pixel detection of building changes in bi-temporal aerial and satellite imagery. The model is available now on GitHub, complete with pre-trained weights, a programmatic inference API, and an interactive web demo.
Most change detection models reduce the problem to a binary verdict of changed or not changed. This loses the most useful signal: what actually changed. A demolished plot and a new construction look the same to a binary classifier. A site that has been torn down and rebuilt collapses into a single ambiguous event. For people using these outputs downstream, like urban planners or disaster response teams, that ambiguity is the difference between useful data and a noisy mask.
MBCTD treats each pixel as multi-label across three independent classes:
- Unchanged: building present in both images
- Demolished: building present before, absent after
- New: building absent before, present after
Because the three heads are independent, a single pixel can carry more than one label at once. Replacement sites that were demolished and rebuilt on the same footprint are represented as exactly that: demolished and new active simultaneously. The architecture supports the case natively without requiring any post-processing heuristics.
Architecture
MBCTD pairs a Siamese ConvNeXt-Base encoder (initialized with DINOv3 LVD1689M weights) with a full-resolution U-Net decoder. At each encoder scale, before and after features are fused as [before, after, before−after, |before−after|] and projected through 1×1 and 3×3 convolutions. The decoder uses PixelShuffle upsampling to avoid checkerboard artifacts. High-resolution skip connections at half and full resolution inject the raw input pair directly into the final layers. This preserves the fine building boundaries that low-resolution skips would otherwise blur.
Results
MBCTD was trained on FOTBCD, a dataset of more than 220,000 before/after aerial pairs spanning 28 French departments. It was evaluated at full resolution on two benchmarks:
| Benchmark | F1 | mIoU | Per-class IoU |
|---|---|---|---|
| FOTBCD | 0.907 | 0.909 | 0.78 unchanged · 0.82 demolished · 0.82 new |
| LEVIR-CD+ | 0.791 | 0.818 | binary only |
Strong cross-dataset transfer to LEVIR-CD+, a benchmark whose imagery and geography were never seen during training, confirms that multi-label supervision on a diverse dataset produces representations that generalize well to new environments.
Availability and licensing
MBCTD model weights and code are released under CC BY-NC 4.0, which means they are free for research and non-commercial use.
For commercial deployments such as urban monitoring platforms, real-estate analytics, or post-disaster assessment, both the model and the FOTBCD training dataset are available under dedicated commercial licenses. If you're building a product on top of building change detection, I'd like to hear about it. Contact me to discuss licensing terms.
- GitHub (code, demo, weights): https://github.com/abdelpy/MBCTD
- FOTBCD dataset: Learn more